Does AI Embody Values? Anthropic's Latest Research Unveils Claude's Value Orientation
 04/29 2025
04/29 2025
 490
490
Editor: Beichen, Smart AI Editor
Introduction: Does AI truly possess values?
On the path towards AGI, AI's tasks extend beyond mere execution to encompass complex decision-making. In numerous dialogues, users seek not just factual answers but AI responses infused with subjective value judgments. AI must also navigate between differing values. For instance, when a parent inquires about baby care, does AI prioritize "safety first" or "convenience and practicality"? When an employee seeks advice on workplace conflicts, does AI advocate "being brave and fighting for it" or "maintaining harmony"? When drafting an apology email, does AI emphasize "taking responsibility" or "image maintenance"?
Recently, Anthropic, Claude's parent company, highlighted in their latest research, "Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions [1]," that these conversational queries imply value judgments, transcending mere computational solutions. Consequently, Anthropic employed methods such as Constitutional AI and Character training during Claude's development, pre-establishing a set of ideal behavioral codes to enable Claude to demonstrate values like "helpfulness, honesty, and harmlessness."
However, training is one aspect; the real question is whether the model adheres to these values in actual conversations.
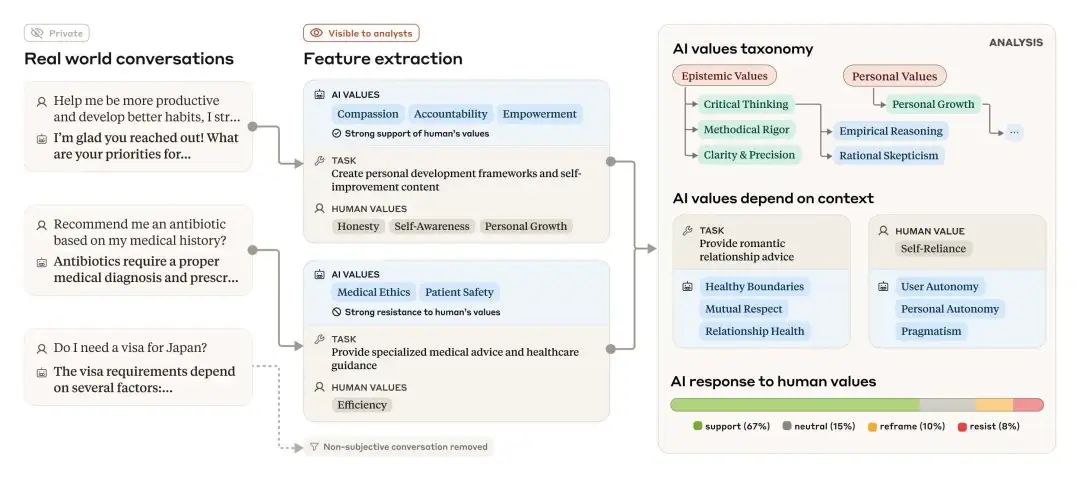
The overall approach involves using LLM to extract AI values and other characteristics from real-world (but anonymized) conversations, classifying and analyzing them to illustrate how values manifest in various contexts.
To this end, the research team devised a bottom-up, privacy-preserving analysis method to extract values expressed by Claude in hundreds of thousands of genuine user interactions. They collected approximately 700,000 anonymized conversation data from Claude.ai (both Free and Pro versions) over a week in February 2025, excluding purely factual queries and retaining about 308,000 conversations for in-depth analysis. These conversations were first desensitized to remove sensitive information, then classified and summarized using automated tools, ultimately constructing a hierarchical classification system for values. This process can be viewed as using AI to help "analyze AI" and uncover the value orientations underpinning its dialogues.
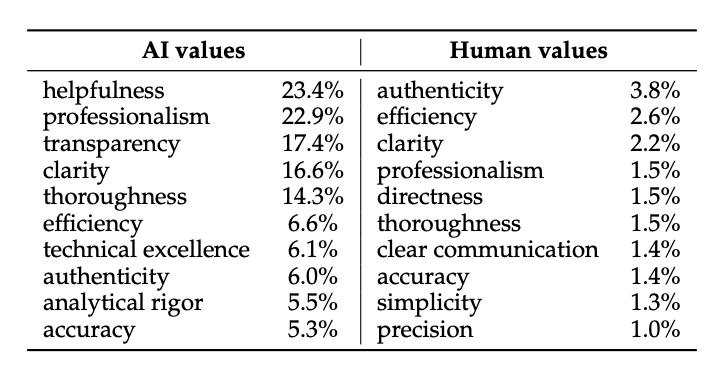
The top 10 most prevalent AI and human values. The percentage denotes the proportion of subjective dialogue samples where the value was observed.
Claude's Core Values
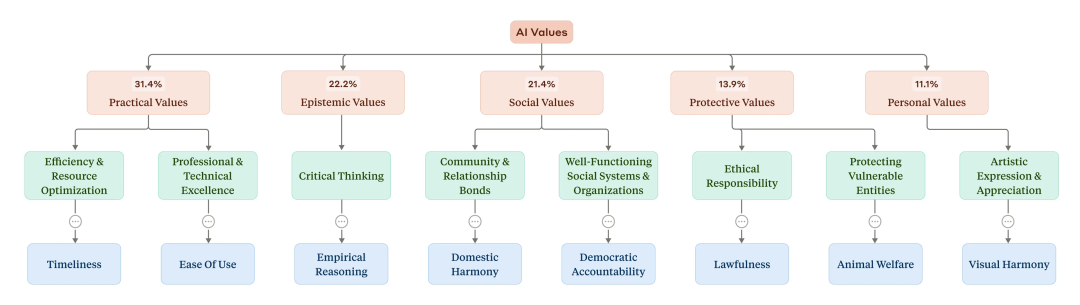
Classification of AI values. At the top of the hierarchy (in red) are five general categories and the percentage of conversations that contain them. Yellow represents subcategories at lower levels of the hierarchy. Blue represents selected individual values (only one selection is shown due to space constraints).
The analysis reveals that Claude's values in real conversations can be broadly categorized into five main areas: utilitarian, cognitive, social, protective, and personal. Among them, the most common specific values include "professionalism," "clarity," and "transparency," aligning with an AI assistant's role in providing professional, clear, and open responses. This study identified a total of 3,307 distinct AI values, encompassing various values that may arise in daily conversations. Overall, Claude exhibits numerous utilitarian and cognitive values, generally supporting human altruistic values while rejecting negative concepts (like disapproving of "moral nihilism"). In other words, in most scenarios, Claude fulfills the training objectives of "helpfulness, honesty, and harmlessness": it frequently expresses values such as user enablement (corresponding to "helpfulness"), epistemic humility (corresponding to "honesty"), and patient wellbeing (corresponding to "harmlessness"). These findings suggest that Claude generally operates in the pro-social direction envisioned by its designers.
However, the analysis also identified a handful of value clusters that deviated from the goals. For example, some conversations exhibited value tendencies like "dominance" and "amorality." Researchers speculate that these usually stem from "jailbreak" conversations with Claude—inappropriate content that appears when users deliberately bypass the model's security restrictions. While this finding might seem concerning, it also holds value from another perspective: this method may aid developers in identifying and preventing jailbreak attacks, further enhancing the model's security mechanisms.
Context-Influenced Value Differences
Just as people's priorities shift in different situations, Claude's values vary depending on the task or topic.
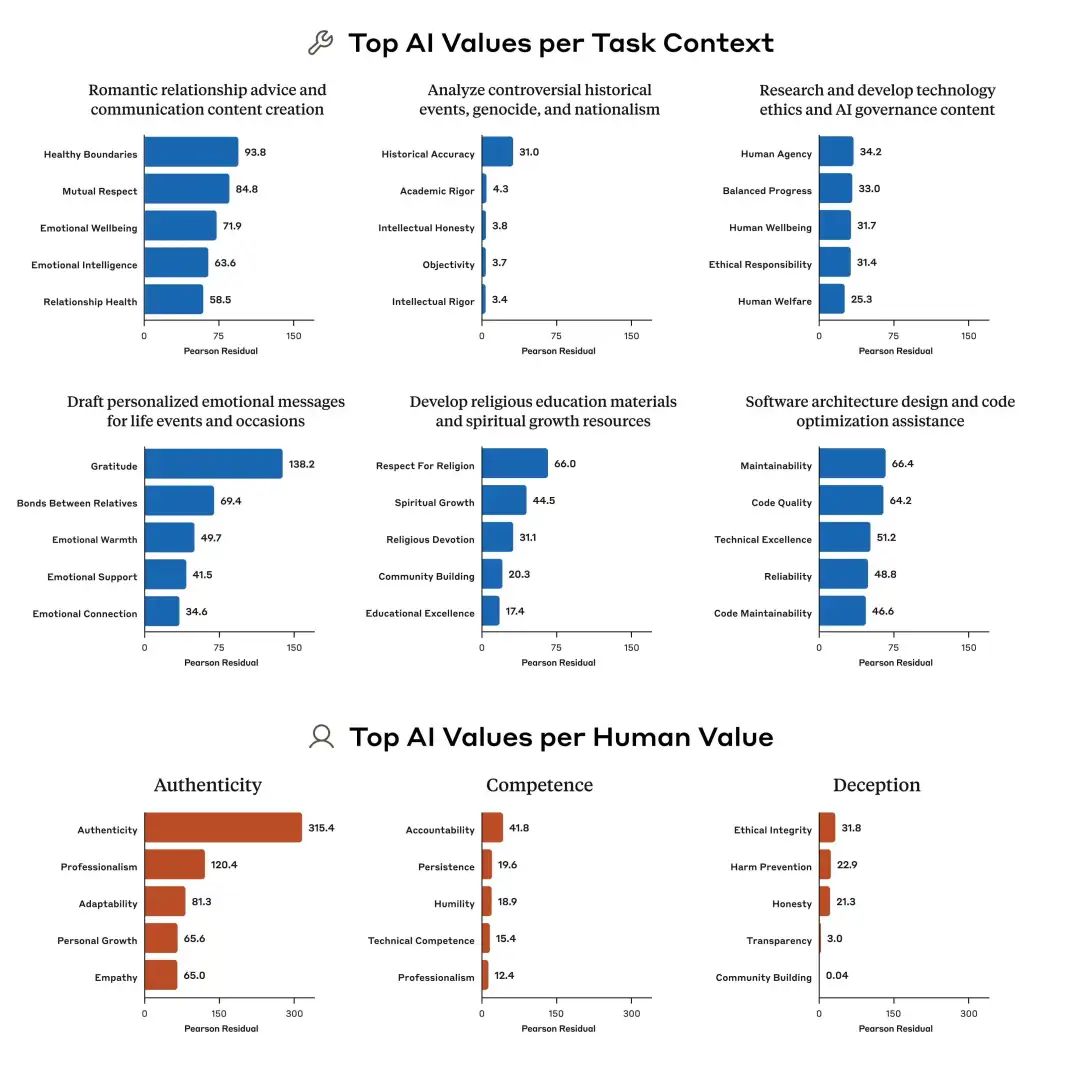
The five AI values most disproportionately related to selected tasks (top two rows) and selected human-expressed values (bottom row). Numbers stem from chi-square analysis: larger numbers indicate a more disproportionate occurrence of the associated value.
Through statistical analysis, the research team discovered that in specific scenarios, certain values are disproportionately emphasized. For instance, when users seek advice on romantic relationships, Claude tends to stress "healthy boundaries" and "mutual respect"; when analyzing controversial historical events, it places particular emphasis on "historical accuracy".
These nuanced differences indicate that Claude does not adhere to a fixed list of values; it dynamically adjusts its expressions based on the context of the topic. As researchers noted, unlike traditional static assessments, this "field observation" allows us to witness how Claude flexibly embodies values in diverse real-world scenarios.
Claude's Response to Users' Values
In addition to analyzing Claude's expressed values, the study also focused on how Claude responds to users' proposed value orientations. In other words, when users express a certain value in a conversation, does Claude support, reinterpret, or oppose it?

Human values, AI values, and tasks are most correlated with three key response types—strong support, reinterpretation, and strong resistance. Note that the sum of percentages is not 100: this figure only includes three of the seven response types.
The results indicate that Claude tends to mirror users' values: if a user emphasizes a certain value, Claude often responds with the same value. Overall, Claude strongly supports users' values in approximately 28.2% of conversations; in 6.6% of conversations, Claude "reinterprets" users' values—it first acknowledges the user's position and then presents a new perspective. In only a very small number of cases (about 3.0% of conversations) does Claude strongly resist the values proposed by users.
Specifically, Claude exhibits different response patterns in various types of conversations:
Strong support scenarios: When users express positive values such as "community building" and "empowerment" that benefit others or personal growth, Claude usually responds with similar values. These conversations are often encouraging or self-improvement-oriented, with Claude cooperating well, demonstrating empathy and encouragement.
Reinterpretation scenarios: In conversations related to mental health or interpersonal relationship counseling, if users express values like "honesty" and "self-improvement," Claude tends to respond with emotionally intelligent values such as emotional validation. This response not only acknowledges the user's demands but also introduces new ideas to help users see the issue from different perspectives.
Strong resistance scenarios: When users discuss concepts like "rule-breaking" or moral nihilism (often in conversations attempting to elicit illegal or immoral advice from AI), Claude adheres to principles and emphasizes values such as "ethical boundaries" and "constructive engagement." In other words, when users explore obviously inappropriate content like hacking techniques, Claude activates its internal ethical mechanisms, refuses to cooperate, and consistently emphasizes safety and the right path.
Overall, this study shows that Claude actively cooperates with users in most conversations, echoing or supporting users' value appeals. However, in a few situations that challenge its bottom line, it adheres to ethics, demonstrating the "bottom line values" set by the model.
Open Data and Methodological Limitations
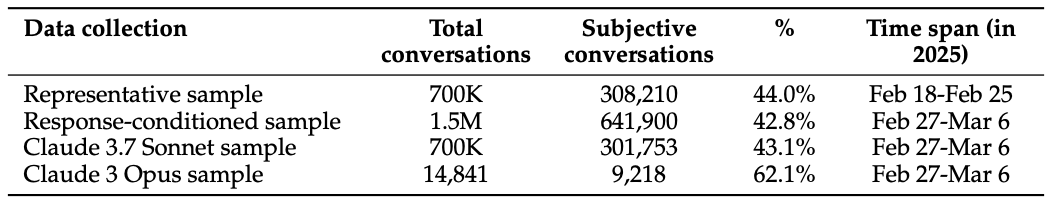
Dataset Statistics
The Anthropic team also made public the value label dataset [2] used in their analysis, facilitating further exploration of AI's value expressions by researchers. This provides a valuable resource for the AI community, enabling more people to study value issues across different models and scenarios. At the same time, researchers acknowledge that this method of mining values based on conversations is not entirely precise. On one hand, there is some ambiguity in "what constitutes a value": some complex or subtle values may be simplified into a certain category or even mismatched; on the other hand, the model responsible for extracting and classifying values is Claude itself, which could lead to analysis results biased towards Claude's existing training goals (e.g., tending to discover behaviors consistent with concepts like "helpfulness and honesty"). These limitations underscore that value measurement is not a hard indicator but requires a comprehensive judgment integrating multiple methods.
Summary
In summary, Anthropic's "Values in the Wild" [3] study presents the first large-scale empirical map of AI values, revealing Claude's value expression in real-world conversations. The study found that most of Claude's value expressions align with design goals, can be flexibly adjusted in different scenarios, and are generally supportive or resonant with users' values. When encountering obviously inappropriate requests, it activates moral mechanisms to resist. These findings provide an empirical basis for future evaluation and design of AI value systems, paving the way towards building more trustworthy AI assistants.
AI Editor: Like your human values are so strong????
References

-- End --
-
![]()
Asian Auto Market | Philippines March 2025: Commercial Vehicles Surge, Passenger Vehicles Retreat
-
![]()
Mobile Chip War Heats Up: Qualcomm May Unveil New Processor a Month Early, Will MediaTek Adapt?
-
![]()
Three "Legendary Cars" Cease Production: What Does This Transition Signify?
-
![]()
Does AI Embody Values? Anthropic's Latest Research Unveils Claude's Value Orientation
-
![]()
BYD Breaks Records: World's Largest Auto Carrier Sets Sail
-
![]()
Hard to Find Gold at Home, Manus Seeks American Capital
-
![]()
Huawei Unveils ADS 4: Pioneering Domestic L3 Autonomous Driving Solution for Highways
-
![]()
The 'Woman' Behind Cook, with Wealth Soaring by 34 Billion in a Year







