GPT-4o: How It Revolutionized Image Creation, Stealing Midjourney's Thunder
 04/14 2025
04/14 2025
 510
510

On March 26, 2025, OpenAI unveiled GPT-4o's native multimodal image generation capability. Users no longer need to switch to DALL-E; they can now create and edit images directly within the ChatGPT application, using 4o.
Overnight, social media platforms like X were flooded with AI-generated Ghibli-style images, captivating internet users with their gentle, anime-inspired charm. By simply uploading a selfie and specifying the "Ghibli" style, users transformed their appearance into Miyazaki's fantastical animations. Even OpenAI's founder, Altman, joined in, sharing his own Ghibli avatar, further fueling the trend.

While the popularity of Ghibli-style images is noteworthy, GPT-4o's drawing capabilities have significantly disrupted the text-to-image landscape, posing a major challenge to Midjourney, a leading vertical application in this field.
Previously, Midjourney users faced a critical issue: excessive randomness. Complex prompts often resulted in a loss of detail. GPT-4o's enhanced image control capabilities, however, allow users to experience the joy of precisely refining images through multiple rounds of dialogue with an AI artist.
So, how did GPT-4o, a general-purpose large model known for its conversational abilities, surpass Midjourney, a specialist in text-to-image generation?

A year ago, applications like Midjourney could already generate images in various styles, including Ghibli, cyberpunk, and surreal, and even slightly outperformed GPT-4o in terms of image delicacy and resolution. However, GPT-4o's cleverness lies in not directly competing with Midjourney on art quality but rather in surpassing it in application thresholds, image editing, interdisciplinary capabilities, and other niche areas.
First, GPT-4o's improved natural language dialogue capabilities significantly lower the barrier to entry. In the traditional text-to-image field, users must master complex structured prompt instructions, including style, camera angle, color, perspective, background, and subject. GPT-4o, on the other hand, can understand natural language commands, allowing users to interact like friends and instantly create images with verbal instructions.
Natural language is everyday speech, the colloquial language of daily life. For example, if you need a waterfall image, you can simply tell GPT-4o, "Help me generate a rainbow waterfall in a dense forest at dawn." In contrast, with Midjourney, you would need to use a highly structured prompt, specifying the subject, background color, camera angle (upward, downward, or level), style (oil painting, classical, or cyberpunk), etc., to achieve the desired effect. Even with such detailed instructions, irrelevant elements might still appear, detracting from the image.

Second, GPT-4o's multimodal capabilities introduce image-to-image and image editing functions. Applications like Midjourney only accept text instructions and do not support uploading an image for modification or adjusting the image's resolution, color, or background after AI generation. If the generated image is not satisfactory, users must rewrite the prompt, essentially discarding the previously generated image.
GPT-4o's strength lies in its ability to allow users to upload any image for multiple modifications, whether AI-generated or self-taken. For example, you can upload a full-body photo, change the hairstyle to big waves, and replace the clothes with a dress from your shopping cart to see the effect. It supports editing existing images, eliminating the need to learn complex image editing techniques like Photoshop.
Even more impressive is its ability to support multiple rounds of dialogue, allowing unlimited modifications to the original image until satisfaction. You can change the hairstyle, replace the background with a desert, or adjust the filter style at will. GPT-4o does whatever you ask.

Image source: Xiaohongshu @Mr. Tang
Besides lowering the interaction threshold and enhancing image control capabilities, GPT-4o's interdisciplinary knowledge base is also impressive. Integrating the original knowledge base of the large language model, GPT-4o is like a painter who knows both astronomy and geography. It can solve advanced mathematics problems, do physics problems, and even restore architectural sketches. In contrast, as a vertical application, Midjourney is always limited to the art field, serving the entertainment and advertising industries.
How powerful is GPT-4o? It can generate function images given a problem, functioning like a drawing-guided photo search app. Even if you give it a colorless pencil sketch of a building, it can generate a realistic post-construction image, completely crossing disciplinary boundaries and demonstrating both liberal arts and science skills.
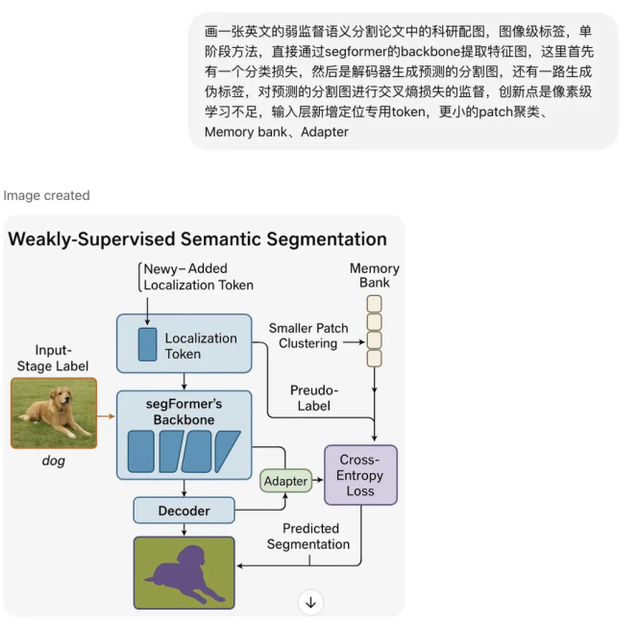
Image source: Xiaohongshu @Yun'an
Given GPT-4o's stunning image generation and editing capabilities, we must ask: What practical value does it bring to ordinary people behind its popularity?

Within a week of its launch, Midjourney CEO David Holz couldn't sit still, posting that GPT-4o was just a show and that Midjourney-v7 would be launched the following week.
It's too early to say which is better between GPT-4o and Midjourney. However, it's certain that GPT-4o has gone viral, breaking out of the niche circle of designers and entering the work scenarios of most people. Even those who don't know what AI image generation is must have heard of this online tool that can edit images with voice commands on social media.
So, why is GPT-4o so popular, and what is its most practical value to us?
First, it truly achieves zero-threshold application. Users don't need any artistic background or AI knowledge; even ordinary people with no foundation can use it directly. With Midjourney, you must know basic painting knowledge like genres, colors, optics, and frameworks, as well as basic English prompt instructions like /imagine (generate image) and --ar (image aspect ratio). But with GPT-4o, you don't need to understand perspective, frameworks, lighting, or structured prompts. You can edit images just by chatting like with a friend.
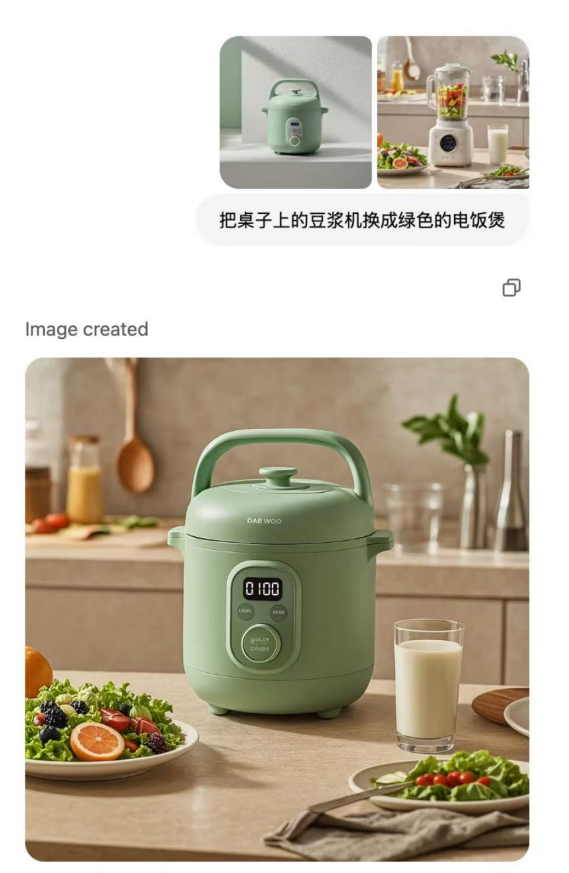
Image source: Xiaohongshu @Geek4Fun
Besides lowering the usage threshold, the quality and efficiency of the model product have also been significantly improved. First, image generation is faster. Previously, it took about 1 minute for Midjourney to interpret complex instructions, but GPT-4o can restore them within 20 seconds.
Second, the control over image generation and editing has increased. GPT-4o can fully restore the instructions you give it. For example, with the same instruction, "Generate a scene of a cat and a dog playing in the grass," GPT-4o will generate an image of a cat and a dog playing on the grass without any other sudden elements, whereas Midjourney might add a park or building to the grass, not fully adhering to the instructions. In layman's terms, GPT-4o listens to you better. It's like your electronic servant; it does whatever you ask and nothing more, with enhanced accuracy.
Thus, GPT-4o opens up the universal race and enters our work scenarios. Previously, ordinary users used Midjourney more out of interest, with strong entertainment attributes and weak tool attributes. Although the generated oil paintings, anime, and other styles of images were beautiful, they neither improved work efficiency nor earned money, mainly serving an aesthetic purpose.

GPT-4o's voice-activated image editing allows AI drawing to be applied to more industries, shifting from entertainment and artistry to professionalism and productivity, with applications in e-commerce, education, architecture, design, and various other industries. For example, if your child struggles with a problem, you used to need to consult a tutor or download Zuoyebang, which is expensive and only provides dry text explanations. But GPT-4o can generate an explanatory draft image, showing how the function is generated and how the answer is derived, with a smooth and natural derivation process.
Another example is promotional posters for the e-commerce industry. Suppose a client needs you to generate an English poster targeting the European and American markets, requiring localized refinement of design elements and language. The previous process involved coordinating with a designer to modify elements, using translation software to refine the text, and then importing it into Photoshop for final adjustments, which is time-consuming and labor-intensive. But now, GPT-4o can design a poster that meets the requirements with just one sentence: "Change this poster to a European and American style and make the language English." Its cross-domain and interdisciplinary integration capabilities are very powerful.

After discussing GPT-4o's breakthrough in image drawing, let's talk about what else can be explored with GPT-4o as an underlying model.
As we all know, Midjourney is an application built on a model, but GPT-4o is a model itself, with image generation being one of its capabilities. When ChatGPT debuted in 2022, it was just a text-based chat assistant. Later, it could make voice calls, and now it can draw images, continuously iterating and upgrading in different dimensions.
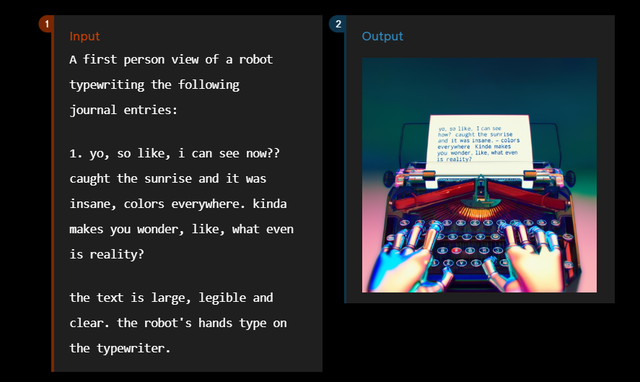
GPT-4o's ability to stand out in the image drawing field is thanks to the significant emergence of its native multimodal model capabilities. Unlike Midjourney, GPT-4o has more technical paths to explore. The current underlying model commonly used in the text-to-image field is the diffusion model, which works by first generating a rough image and then eliminating noise, like painting in the snow or seeing flowers through fog, with limited restoration capabilities. GPT-4o, however, uses the autoregressive model for text-to-image, extending the logical reasoning ability of previously predicted tokens to the text-to-image field. By drawing frame by frame and predicting the next pixel from the already generated pixels, it essentially mimics human drawing. This means that unlike vertical applications, large models can choose different technical paths from the underlying architecture, and architectural upgrades usually lead to performance leaps. Functions based on native models like GPT-4o have more room to grow.
Second, multimodal fusion will lead to cross-domain integration. As a general large model, GPT-4o has the ability to integrate information in different formats such as text, audio, and images. At this stage, it can already make phone calls, generate and edit images. In the future, it's worth expecting whether it can directly generate music and videos. In fact, GPT-4o's newly launched image generation function is derived from OpenAI's text-to-image model DALL-E. Perhaps OpenAI's text-to-video model Sora may also be integrated into the GPT model through some technology. At that time, cross-processing multiple modal information within one model will no longer be far-fetched.
Moreover, multimodal innovation further illustrates that as models become multifunctional, their ability to handle various tasks becomes stronger, leading to lower overall AI usage costs. A foreseeable trend is that large models are attempting to become one-stop shops, integrating tasks such as coding, design, music, and data processing. Perhaps one day in the future, models like ChatGPT will be so powerful that they can rank among the top three in any field. We will no longer need to download vertical applications like Midjourney for drawing, Coze for coding, or Suno for music; instead, we can solve all problems by directly downloading a model like ChatGPT. This will increase phone memory, improve operating efficiency, and save around $10 per month on subscription fees for vertical applications, offering higher cost-effectiveness.

In short, the emergence of GPT-4o's drawing capabilities highlights the ability of underlying large models to integrate multiple applications. The vision derived from this capability is that in the future, we can simultaneously utilize multidimensional abilities such as drawing, music, and coding within a one-stop model. Moreover, the threshold for using it is extremely low, so low that anyone without a technical background, or even someone unfamiliar with AI, can use it.
And perhaps this is the ultimate goal of human invention of AI - to make technology accessible to every corner.

-
![]()
Allegro Enhances Motor Control and Thermal Management Solutions for EV and Automation Growth
-
![]()
ARBURG Exhibits at Chinaplas 2025
-
CHINAPLAS 2025: BASF Embraces #OurPlasticsJourney, Advancing Towards a Net-Zero Emission Future Through Sustainable Innovations and Collaborative Efforts
-
![]()
Tariff shock looms, crisis and opportunity for cross-border merchants
-
![]()
Market Value Halved: Li Auto Faces Mounting Pressures
-
![]()
Nezha Auto's Darkest Hour: Triple Collapse in the Survival Game of New Forces
-
![]()
2025 European EV Rankings in Q1: Another Steep Decline! Chinese Cars Absent from Top 10, Volkswagen Outpaces Tesla
-
Skyworth, a TV Manufacturer, Scoring Big in the Middle East Auto Market?





